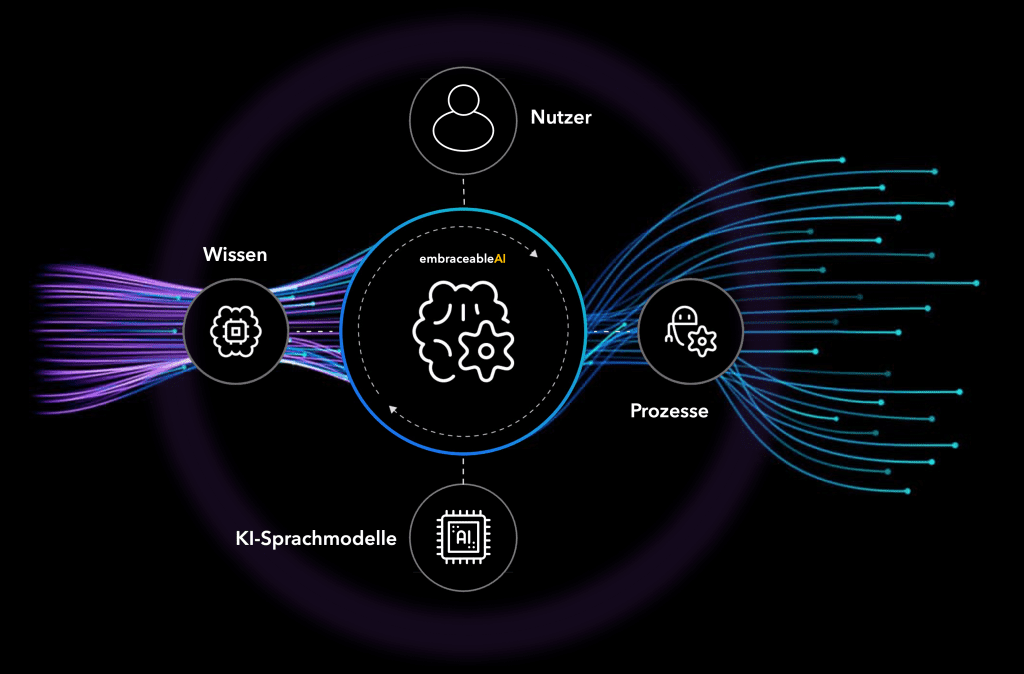


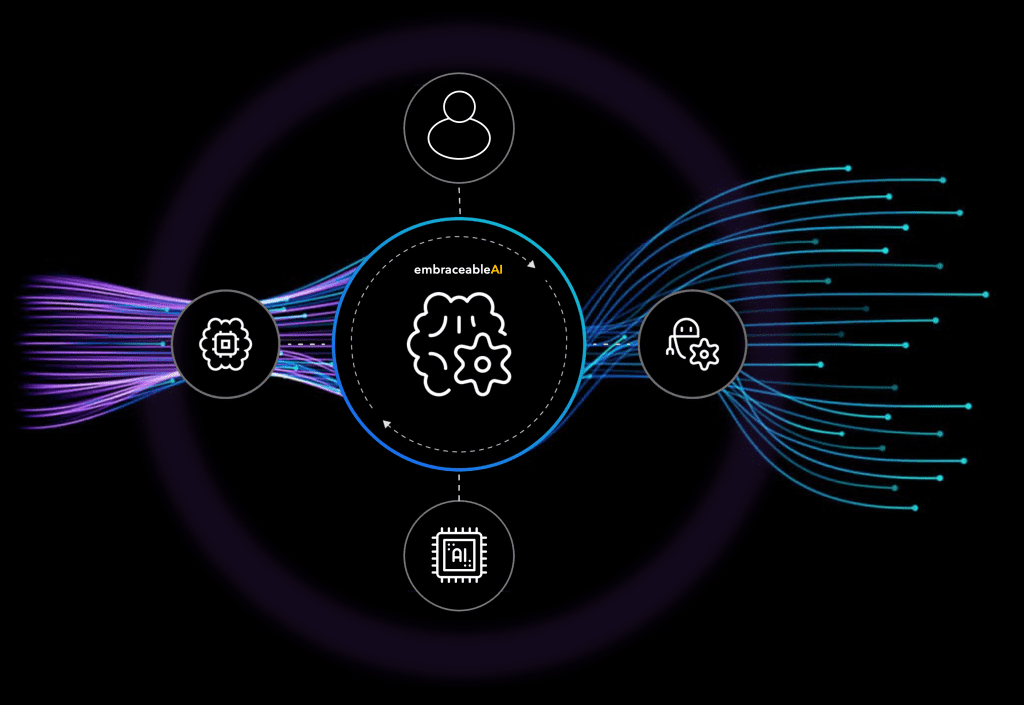
Sie binden Ihre Dokumente an.
Sie binden Ihre Bestands-Systeme an.
Sie binden KI-Sprachmodelle an.
Unser System steuert und überwacht die
Datenflüsse zwischen allen Komponenten
Der so genannte "Cognitive Nexus" steht sinnbildlich
für die Individuelle Digitale Intelligenz Ihrer Organisation.
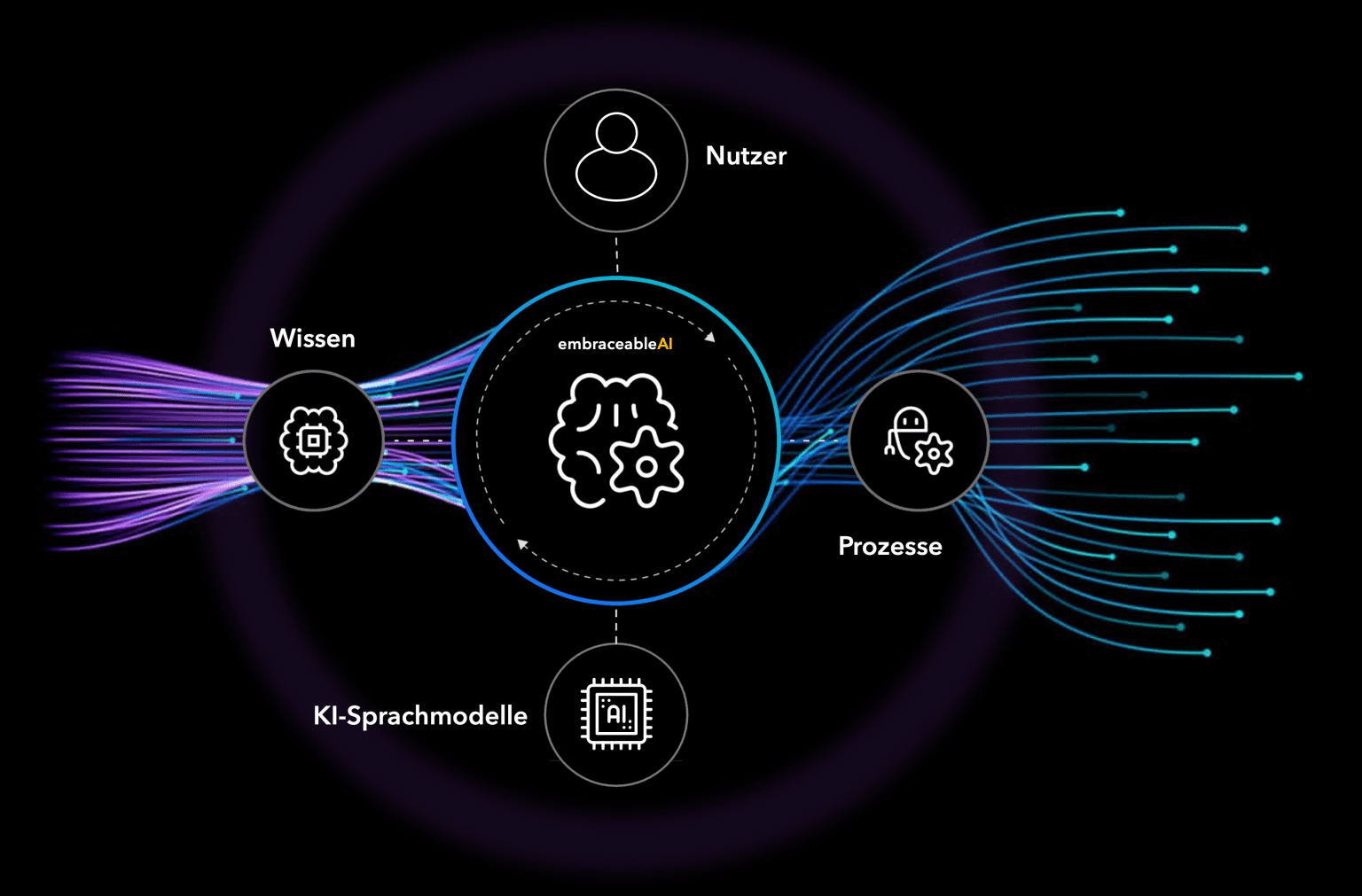
Sie binden Ihre
Dokumente an.
Sie binden Ihre
Bestands-Systeme an.
Sie binden KI-Sprachmodelle an.
Unser System steuert
und überwacht die
Datenflüsse zwischen
allen System-Komponenten
Der so genannte
"Cognitive Nexus" steht
sinnbildlich für die
Individuelle Digitale Intelligenz
Ihrer Organisation.
embraceableChat
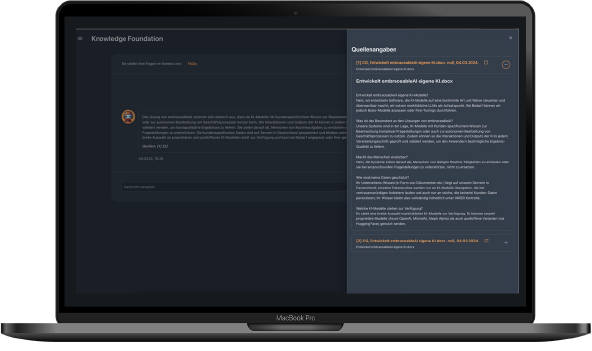
Knowledge API
MicroWorker API
embraceableChat
Knowledge API
MicroWorker API
embraceableChat
Knowledge API
MicroWorker API
embraceableChat
Knowledge API
MicroWorker API

Allgemein
KI-Modelle (Auszug)
Cloud-Provider / Infrastruktur-Optionen
Allgemein
KI-Modelle (Auszug)




Cloud-Provider / Infrastruktur-Optionen
